Testing access times to cloud optimized HDF5 files with the fsspec and ROS3 drivers.
This notebook tests both I/O drivers on cloud optimized HDF5 files from the ICESat-2 mission.
Note: The ROS3 driver is only available in the Conda distribution of h5py
In [1]:
import fsspecimport pandas as pdimport matplotlib.pyplot as pltimport h5pyfrom dask.distributed import Client, LocalClusterimport dask.bag as dbfrom dask.diagnostics import ProgressBarfrom h5logger import parse_fsspec_log, read_filefor library in (h5py, fsspec):print(f'{library.__name__} v{library.__version__}')
h5py v3.11.0
fsspec v2024.9.0
The folowing dictionary is generic enough that we can use it for different datasets, we only require file URLS and the variables we want to read from them using h5py. The tests take for granted that the original file has no cloud optimizations and can not be read using cloud optimized patterns, the next check is to verify if the keywords “paged” or “rechunked” are present in the file name, it’s presumed to be cloud optimized.
This notebook uses dask to speed up the testing, we issue requests to each file at the same time, first looping using default parameters, this is to learn what happens when we access the different flavors without knowing that some are cloud optimized. Then we use optimized I/O parameters, we do the same for both fsspec and the HDF5 native driver ROS3.
# If there is a dask_client cluster let's not create new ones.if"dask_client"notinlocals(): cluster = LocalCluster(threads_per_worker=1) dask_client = Client(cluster) dask_client
The importance of caching and over-reads with remote files
simple: Caches entire files on disk.
blockcache: Caches file data in chunks (blocks) on memory.
bytes: Caches entire files in memory.
none: Does not use caching on any request
In [4]:
num_runs =1benchmarks = []ranges = []#the real default is readahead with 5MB of block sizes, we disabled to test real times without caching anythingdefault_io_params = {"fsspec_params": {"skip_instance_cache": True,"cache_type": "none"# "cache_type": "first", # could be first, or cachiing the entier file with simple, # "block_size": 4*1024*1024 },"h5py_params": {}}# we can fine-tune theseoptimized_io_params ={"fsspec_params": {"cache_type": "blockcache", # could be first, or cachiing the entier file with simple, "block_size": 8*1024*1024 },"h5py_params" : {"page_buf_size": 16*1024*1024,"rdcc_nbytes": 4*1024*1024 }}for optimized_read in [False, True]:for driver in ["ros3", "fsspec"]:for run inrange(num_runs): # Running N timesfor dataset_name, dataset_item in test_dict.items():# Inner loop (parallelized) urls = dataset_item["files"].items() benchmark_list = [(run, dataset_name, dataset_item["variables"], flavor, url, optimized_read, driver, default_io_params, optimized_io_params) for flavor, url in urls] bag = db.from_sequence(benchmark_list, npartitions=len(benchmark_list)) result = bag.map(read_file)with ProgressBar(): results = result.compute()for result in results:iflen(result["benchmark"]): benchmarks.append(result["benchmark"])# For now we can only log I/O with fsspecif result["benchmark"]["driver"] =="fsspec": ranges.append(result["ranges"])df = pd.DataFrame.from_dict(benchmarks)
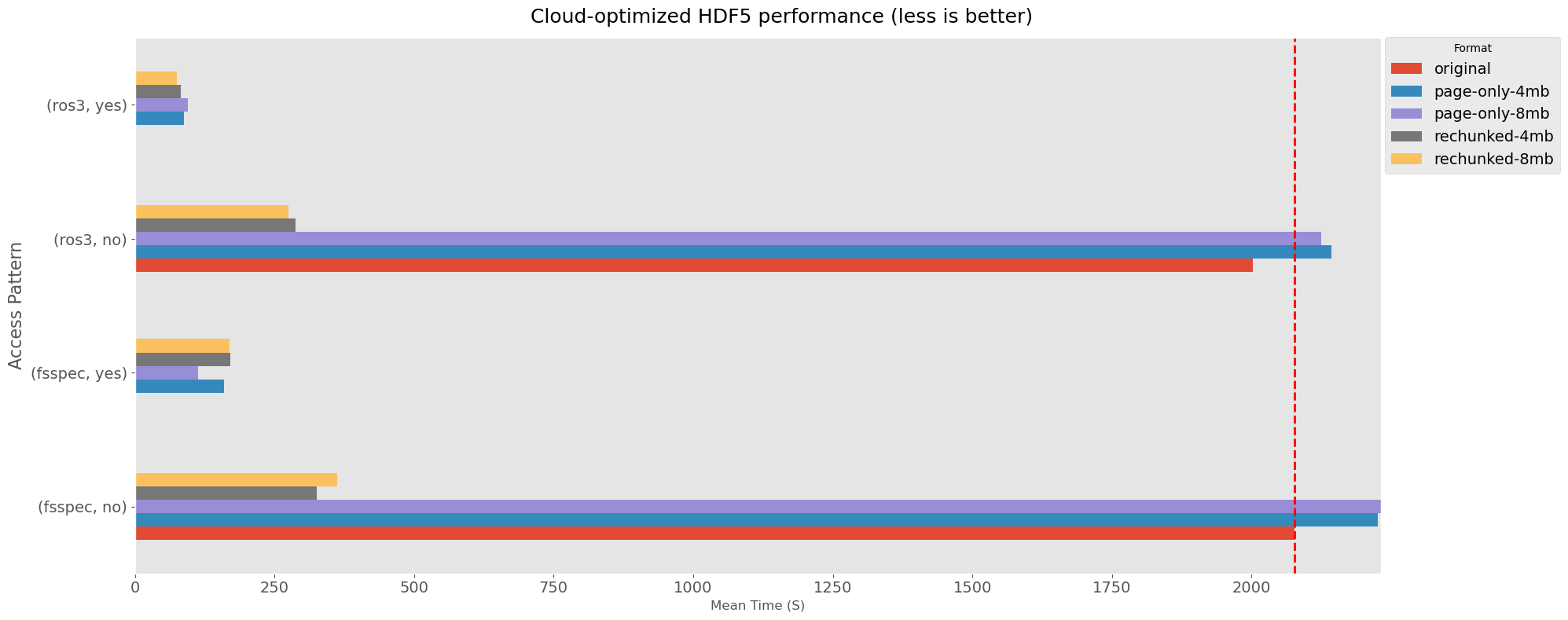
Now that we have collected the information we need we are going to plot how the drivers and the parameters performed. The “baseline” is what HDF5 and fsspec do when they don’t use cloud optimized parameters on a non-optimized file. Here is when we see the worst performance due te many small serial request to cloud storage. Presumably, the best case would be when we use optimized I/O that aligns to the scheme used for a cloud optimized file. E.G. if a file was optimized using paged aggregation and page sizes of 4MB, the best performance should be when we tell the I/O driver that we should read 4MB at the time.
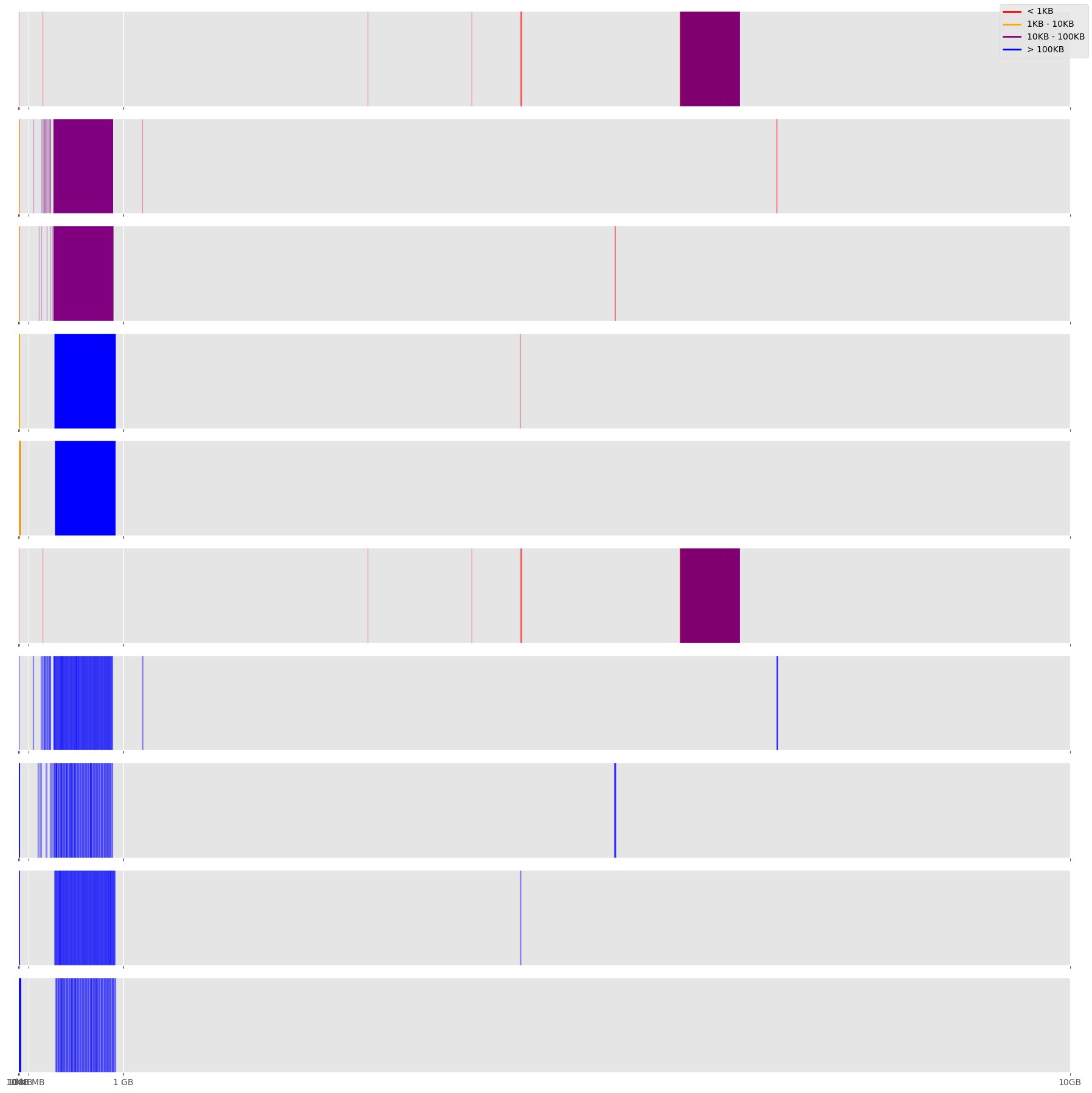
The following cell is experimental, it plots the access pattern signature and the reads on a remote HDF5 file, optimized or not, we can only record the info using fsspec for now as ROS3 logging requires to compile h5py from scratch using custom flags.